Under the hood of to-many relations in Django and filtering with them
I'll build up the information slowly and from basic levels, while mentioning the key points. Feel free to skip the parts you are familiar with.
A "to-many" relation, as its name suggests, refers to the case where an object is related to multiple object under one name. In Django, this can be seen in two forms:
- Reverse
ForeignKeyrelations - Forward or reverse access on many-to-many relations (
ManyToManyField)
However, ManyToManyField is itself implemented using an intermediate model (also known as the "through" model) that has two foreign keys: one to the source model and one to the target model, which means that both models can have a "reverse foreign key relation" toward the intermediate model (which can then be related to the corresponding objects of the other model). It's kind of just case (1) with more steps. This is true even when the source and target models are the same.
I'd like to clarify that by "object", I just mean an instance of a Django model that corresponds to a record or row in the database. I'll use the term "row" if I specifically refer to a database row rather than its representation in Python, and the term "record" to refer to both concepts. Also, what I call a "to-many" relation is referred to as "many" relations in Django's docs.
Reverse ForeignKey relations
You are most likely familiar with this, but a brief explanation shouldn't hurt. Imagine we are developing a blogging system, and we setup our Django models as follows:
class Post(models.Model):
title = models.CharField(max_length=100)
class Comment(models.Model):
post = models.ForeignKey(Post, on_delete=models.CASCADE)
text = models.CharField(max_length=1000)
Django will create a field post_id on Comment that will be the primary key of the post to which it refers. In fact, post_id can be accessed without fully retrieveing the related Post object (and therefore without querying the database):
comment.post_id # == `comment.post.id`
But in order to get the full related Post object, we have to access the attribute comment.post, which will cause a query to the database unless it's somehow already retrieved (i.e., either retrieved at least once, or loaded using select_related(), only() or similar means).
Now let's consider the reverse relation. If we have a Post object named post, then we can get all its comments:
post.comment_set.all()
In the database level, Django simply retrieves all Comment objects whose post_id field refers to the primary key of post, namely post.id. If we assume post.id is 2, then Django will make a query similar to this:
SELECT * FROM "app_comment" WHERE "app_comment"."post_id" = 2;
Many-to-many relations
Django provides the ManyToManyField for many-to-many relations. Let's add a Tag model for our posts as well, where each tag can belong to multiple posts, and each post can have multiple tags:
class Tag(models.Model):
name = models.CharField(max_length=20, unique=True)
class Post(models.Model):
...
tags = models.ManyToManyField(Tag)
It looks like tags is a field on Post, but it's merely Django's way of abstracting away the underlying mechanism. In the database level, no field is created on Post's table. Instead, Django creates an intermediate model that has a foreign key to both Post and Tag, and each record on this model represents a relation between a Post and a Tag, and therefore the collection of all these records (i.e., all the objects of the intermediate model) represents the "many-to-many" relation.
The intermediate model is something like this (Django does this automatically by default):
class PostTags(models.Model):
post = models.ForeignKey(Post, on_delete=models.CASCADE)
tag = models.ForeignKey(Tag, on_delete=models.CASCADE)
But, of course, we don't see this (by default). We can retrieve all the tags of post without knowing about this intermediate model:
# This will give `Tag` objects.
post.tags.all()
But how is this done in the database level? Let's assume post.id is 2. Then, Django makes a query similar to this:
SELECT * FROM "app_tag"
INNER JOIN "app_post_tags" ON ("app_tag"."id" = "app_post_tags"."tag_id")
WHERE "app_post_tags"."post_id" = 2;
where app_post_tags is the table name for the intermediate model. By default, it follows the pattern {app_name}_{first_model_name}_{m2m_field_name}. In this query, we get all the tags that have a corresponding record on the intermediate model, but those intermediate records should refer to the post whose id is 2, thus obtaining all the tags for that post.
For the sake of completeness, let's visualize this as well (it can help in understanding the upcoming sections). Imagine the tables look like this:
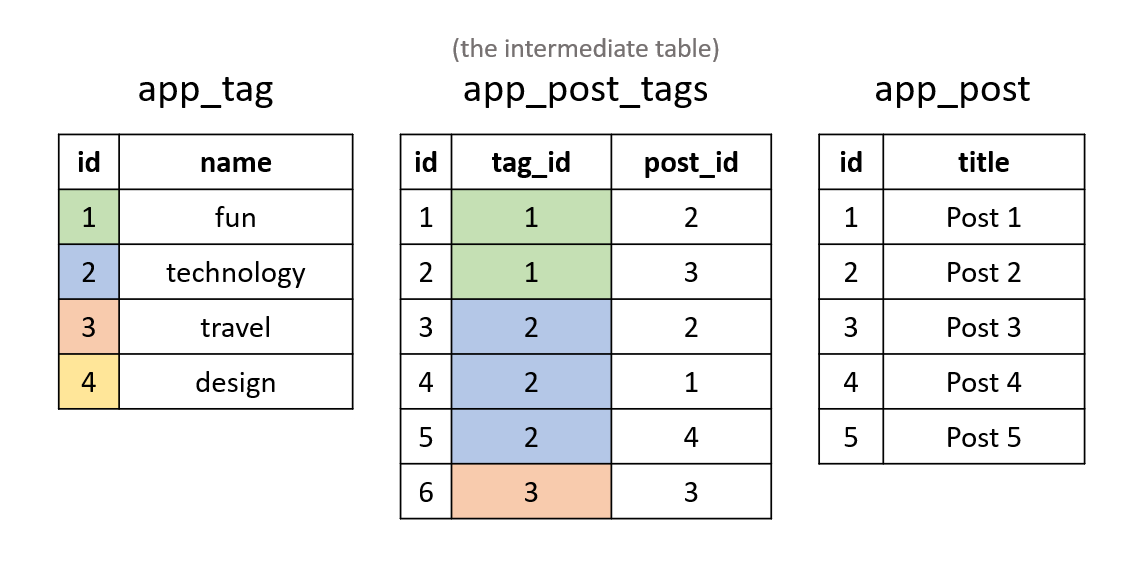
Now, let's first execute the query without the WHERE clause:
SELECT * FROM "app_tag"
INNER JOIN "app_post_tags" ON ("app_tag"."id" = "app_post_tags"."tag_id");
The result should look like this, where the tag rows are duplicated for each corresponding row in app_post_tags (a well-known thing in SQL joins):
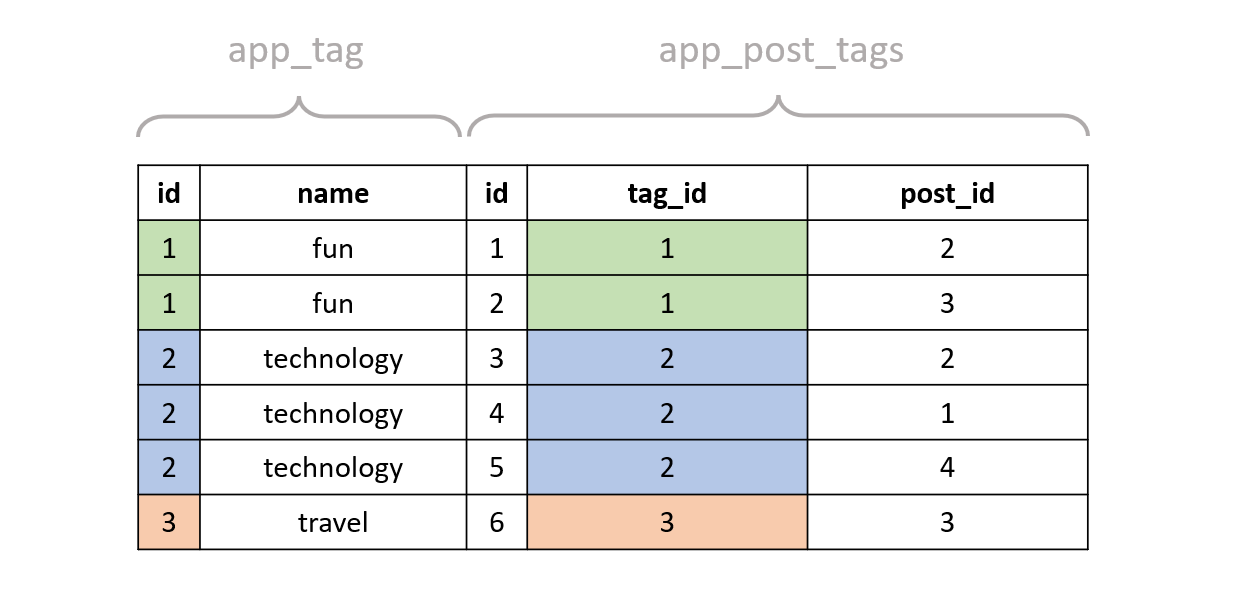
Then, we bring in the WHERE clause as well, which will filter out the last result:
SELECT * FROM "app_tag"
INNER JOIN "app_post_tags" ON ("app_tag"."id" = "app_post_tags"."tag_id")
WHERE "app_post_tags"."post_id" = 2;
And we finally get the tags of our post:
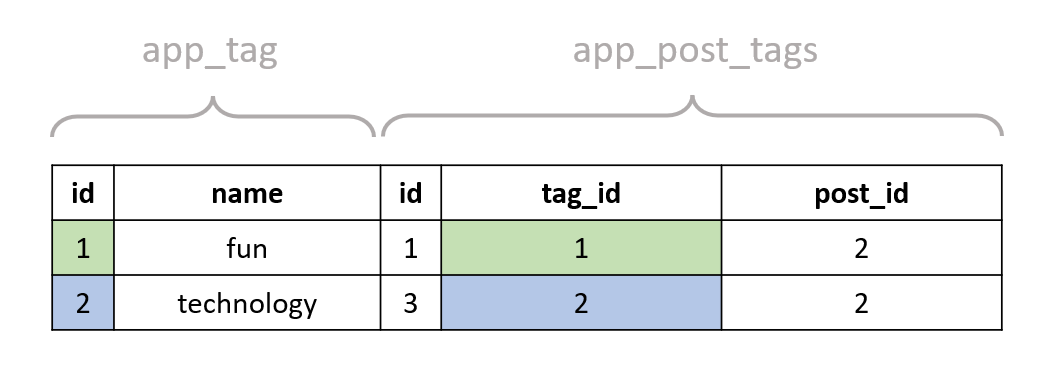
Here we also get the fields from app_post_tags table, but Django actually doesn't even select them; here's the real query Django would execute:
SELECT "app_tag"."id", "app_tag"."name" FROM "app_tag"
INNER JOIN "app_post_tags" ON ("app_tag"."id" = "app_post_tags"."tag_id")
WHERE "app_post_tags"."post_id" = 2;
But, you might ask: why don't we join from app_post_tags to app_tag rather than the other way around? In fact, you absolutely can, as INNER JOIN performs symmetrically after all. Even if you put app_post_tags in your FROM clause instead of app_tag, you can still select the fields you want from the result.
It also doesn't matter to the database which INNER JOIN direction you choose: the result are identical. Django just happens to use this convention possibly because it seems more "natural", in the sense that we want the "tag" objects, so let's put the tags' table in the FROM clause.
In the above example, we tried to get all the tags of a particular post. But we can also get all the posts that have particular tag:
tag.post_set.all()
And the underlying process is exactly the same. It's customary to call this a "reverse" access, but honestly there is no "reverse" or "forward" in a many-to-many relation as it's a symmetrical thing. It's just that we put the ManyToManyField on the Post model, so we might refer to post.tags.all() as being a "forward" access, so the other would be a "reverse" access. But we could have put the ManyToManyField on the Tag model as well, and it's equally valid.
I should finally mention that you can customize the intermediate model. ManyToManyField takes an argument named through, where you can specify your own custom intermediate model for the relation. It's useful when you want to store more information about this relation, or you want to have more direct access to it. The model is required to have foreign keys to both the related models.
Filtering by to-many relations
Continuing from our blogging example, imagine we want to find all the posts that have a tag named "technology", but we don't have the id of the Tag object whose name is "technology". One thing we can do, is to first query the database to find the tag:
tech_tag = Tag.objects.get(name='technology')
And then do tech_tag.post_set.all(). But this results in two queries being made to the database. We can actually do this in a single query. Let's see the code first:
tech_posts = Post.objects.filter(tags__name='technology')
Here, tags specifies a to-many relation since a post can have multiple tags. When dealing with to-many relations in a filter(), it simply denotes having at least one. For example, the filter() above means: find all posts that have at least one tag whose name is "technology". However, this sounds weird because we probably wouldn't allow the same tag to appear twice or more in one post (which correspond to two or more identical records in the intermediate model). But the logic still works: we either have the tag on the post, or we don't have it. In other words, we either have it one time or zero times. So in our example, "at least one" can be translated to "exactly one", but that is not always the case for to-many relations.
This time, let's try to get all the posts that have at least one comment whose text is "perfect". For this, we'll have to write the filter() this way:
Post.objects.filter(comment__text='perfect')
Now that we know about this "having at least one" rule, the meaning of this filter may seem trivial, but it's not. Let me show you with an example:
# Create a post
>>> post1 = Post.objects.create(title='Post 1')
# And add some comments to it
>>> Comment.objects.create(post=post1, text='nice article!')
>>> Comment.objects.create(post=post1, text='perfect')
Now let's try our filter:
>>> Post.objects.filter(comment__text='perfect')
<QuerySet [<Post: Post object (1)>]>
As you can see, we got only one post which was expected: post1 has a comment with the text "perfect". Now, let's add another comment with text "perfect":
>>> Comment.objects.create(post=post1, text='perfect')
And we try the filter again:
>>> Post.objects.filter(comment__text='perfect')
<QuerySet [<Post: Post object (1)>, <Post: Post object (1)>]>
It returned the same post, but twice: we got repetitive results. What is actually going on here? Before explaining that, let's first appreciate the fact that our rule of "having at least one" still applies: even though the same post is returned twice, each of them (which is really just one post) has at least one such comment. But then where do the repetitive results come from? It's all about what's happening in the database level (i.e., the queries that Django makes).
The query is similar to this:
SELECT * FROM "app_post"
INNER JOIN "app_comment" ON ("app_post"."id" = "app_comment"."post_id")
WHERE "app_comment"."text" = 'perfect';
To visualize it, imagine the tables are like in the following image, where we only have 1 comment with text perfect on the post with id == 1.
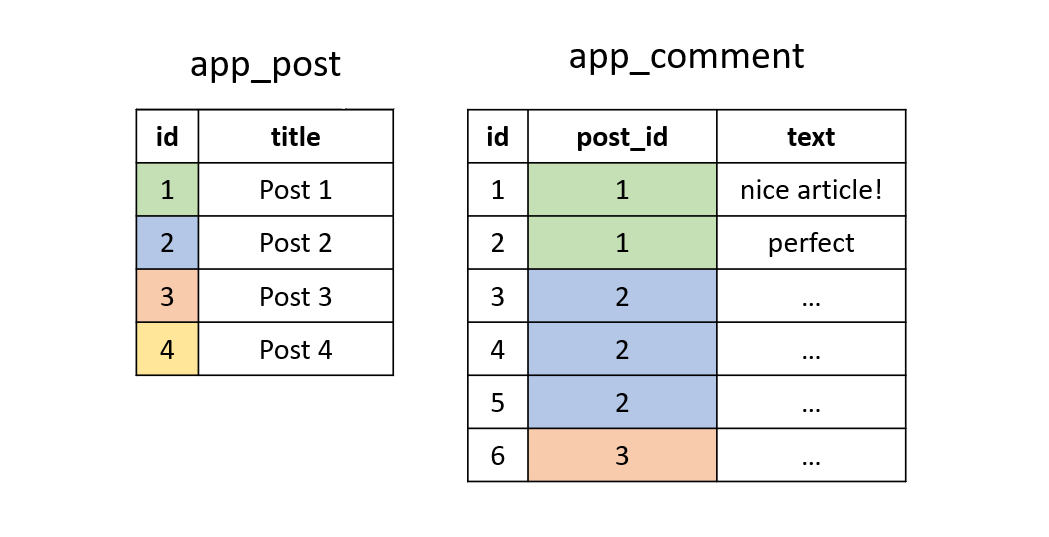
Now let's run the query on them without the WHERE clause:
SELECT * FROM "app_post"
INNER JOIN "app_comment" ON ("app_post"."id" = "app_comment"."post_id");
which should give something like this:
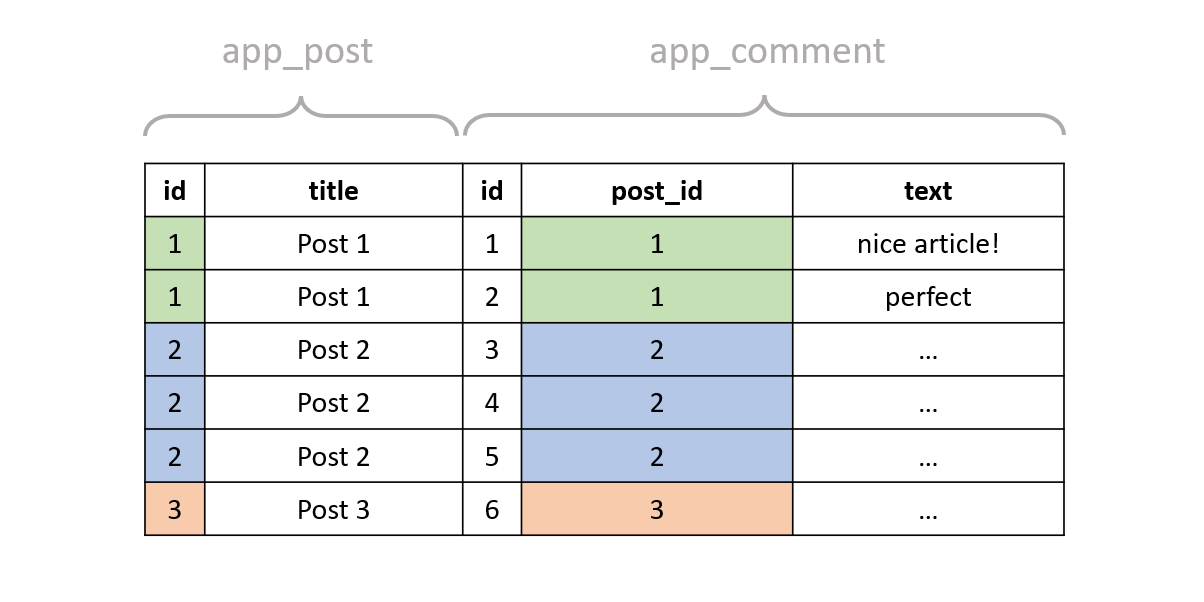
The post rows are duplicated for each comment that refers to that post (similar to the example of the previous section). The post with id == 1 has two comments, and thus the result contains two rows for that post. If we now execute the query with the WHERE clause included, we'll get only one post:
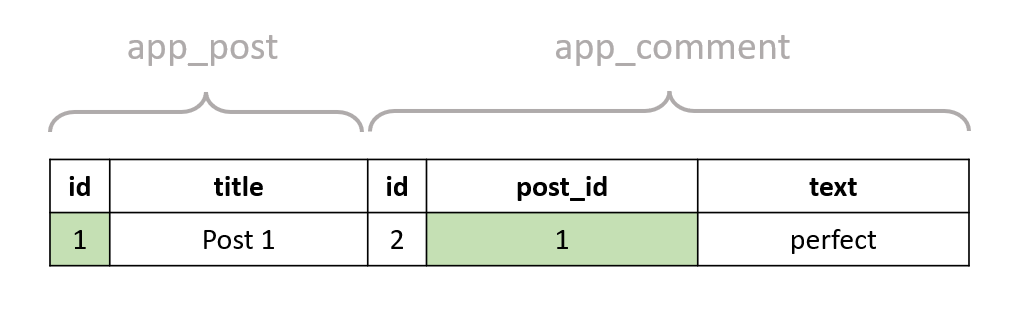
This time, let's imagine our post had two comments with text "perfect" instead (in practice, comments of the same post wouldn't necessarily have sequential id's. It's only to make the example simpler):
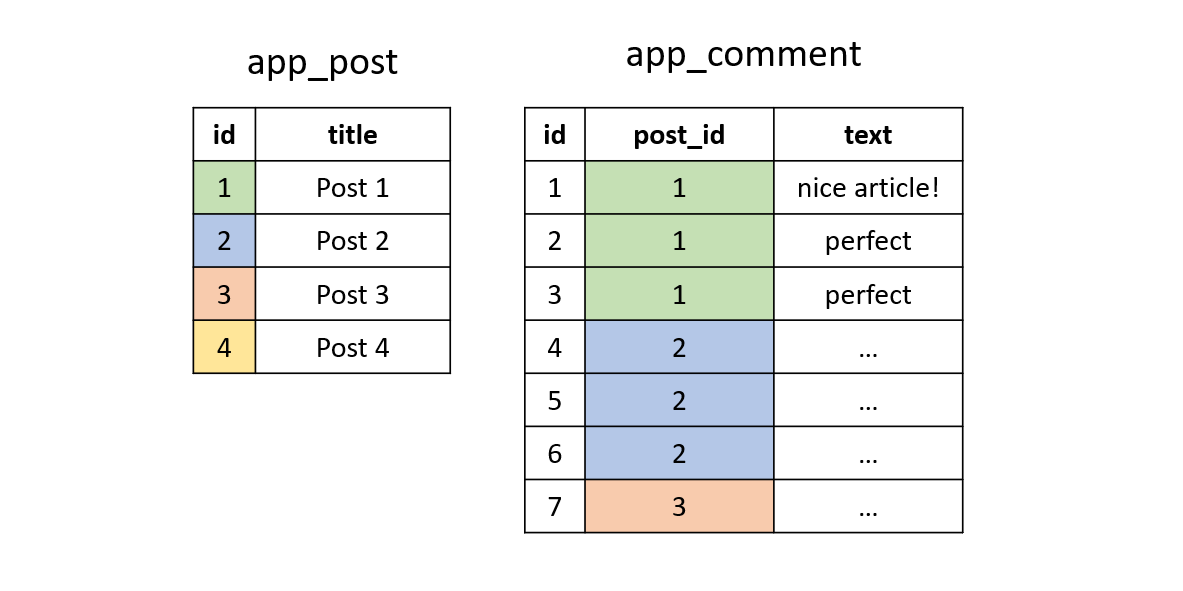
Then we run the INNER JOIN without the WHERE clause:
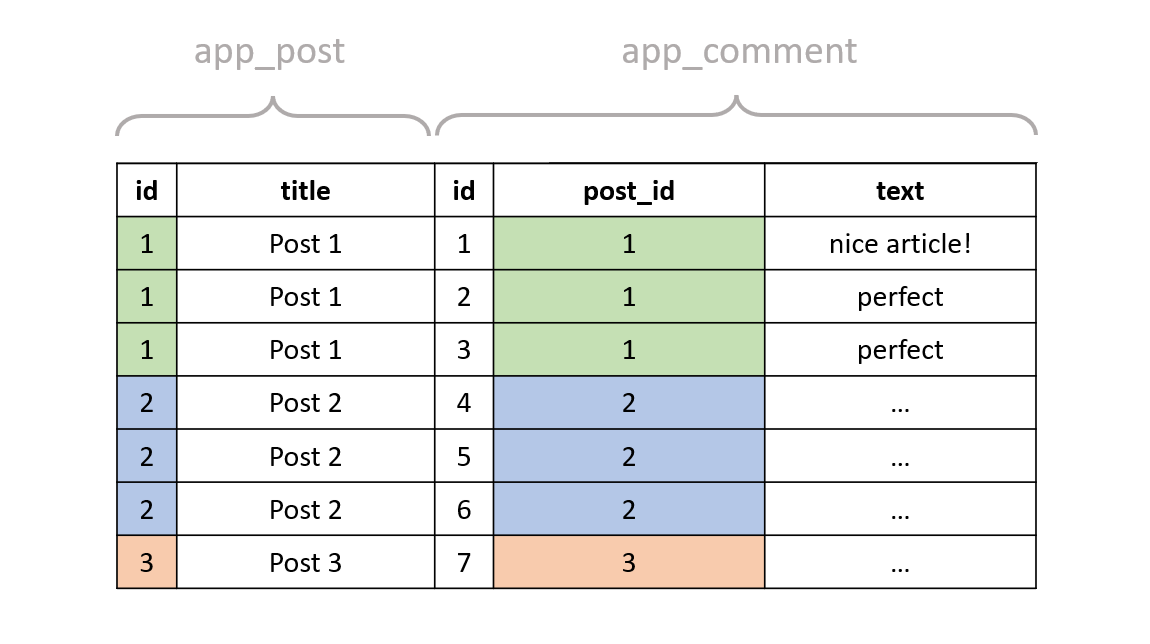
You should be able to see where this is going. Let's finally include the WHERE clause in our query:
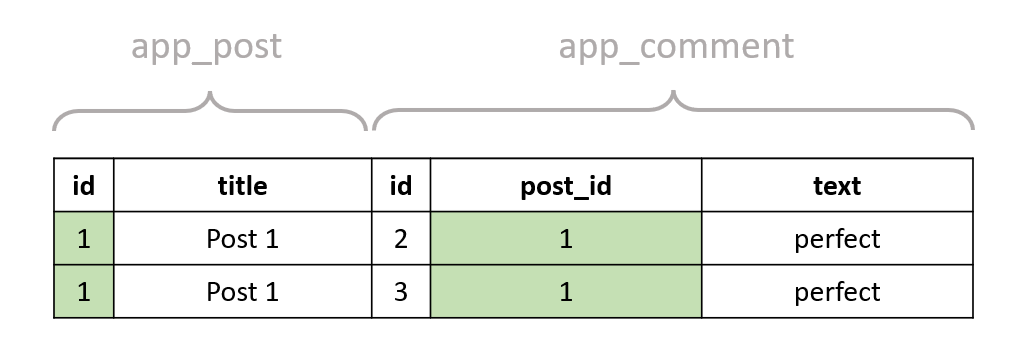
We get the same post twice. Of course, Django will only put the post fields in the SELECT part of the query, so the database only returns the post data. Regardless of that, the underlying process is similar to what I demonstrated.
So, the rule for filtering to-many relations is still "having at least one such that <condition>", but the results will be duplicated for as many related objects as there are. Try to remember this by understanding the underlying process rather than memorizing rules. Rules might have fuzzy meanings or lack enough details, but knowing how the whole thing works enables you to write the correct code to get your desired result.
Deeper relations
The logic explained above also applies when we have deeper relations consisting of multiple to-many and/or to-one relations. However, duplication will happen every time we cross over a to-many relation (by SQL joins). To see this, imagine we add emoji reactions to our comments:
class CommentReaction(models.Model):
class EmojiChoices(models.TextChoices):
LIKE = 'L', '👍'
DISLIKE = 'D', '👎'
emoji = models.CharField(choices=EmojiChoices, max_length=1)
comment = models.ForeignKey(Comment, on_delete=models.CASCADE)
By default, the table name Django will use for this model would be {app_name}_commentreaction. We'll now try and perform a more complicated filter. Let's say we want all the posts which have a comment with a like reaction. More precisely, we want all the posts which have at least one comment with at least one like reaction. Using what we learned so far, we can construct a filter:
Post.objects.filter(comment__commentreaction__emoji='L')
(It's a better practice to use CommentReaction.EmojiChoices.LIKE instead of L, but I want to focues on the actual point). This filter contains two to-many relations:
- Each post has (possibly) multiple comments.
- Each comment has (possibly) multiple reactions.
The query would be something like this:
SELECT * FROM "app_post"
INNER JOIN "app_comment" ON ("app_post"."id" = "app_comment")
INNER JOIN "app_commentreaction" ON ("app_comment"."id" = "app_commentreaction"."comment_id")
WHERE "app_commentreaction"."emoji" = 'L';
As you can see, we have two INNER JOINs, each with a potential to duplicate the results before it. To imagine this in your head, think about it this way (this is only theoretical, and the database engine can obtain the same result in any way it wants):
-
We get all the posts, and to each one, we attach its corresponding comments. As discussed, if a post has no comments, it won't be selected, and if it has more than one comment, it will be duplicated to match the number of its comment. Now, each row of our result contains post fields and comment fields.
-
Next, we take the result of the previous part, and to each row, we attach its corresponding comment reaction. Again, if a comment has no reaction, it would not be selected (which also means that the corresponding post row would be duplicated one less), and if it has more than one reaction, it would be duplicated to match to number of its reactions (which also means that the rows with the corresponding post would be duplicated even further: see below). Now, each row of our result contains post fields, comment fields and comment reaction fields.
-
We finally filter based on the comment reaction field
emoji(using theWHEREclause), where we only choose those rows having a reaction emoji ofL(which is for like).
After step 1, the number of rows corresponding to a particular post was equal to the number of comments on that post. After step 2, the resulting rows of step 1 were duplicated as explained, which means that the number of rows corresponding to a particular post would be the total number of reactions on all of its comments.
Let's visualize this. First, the tables:
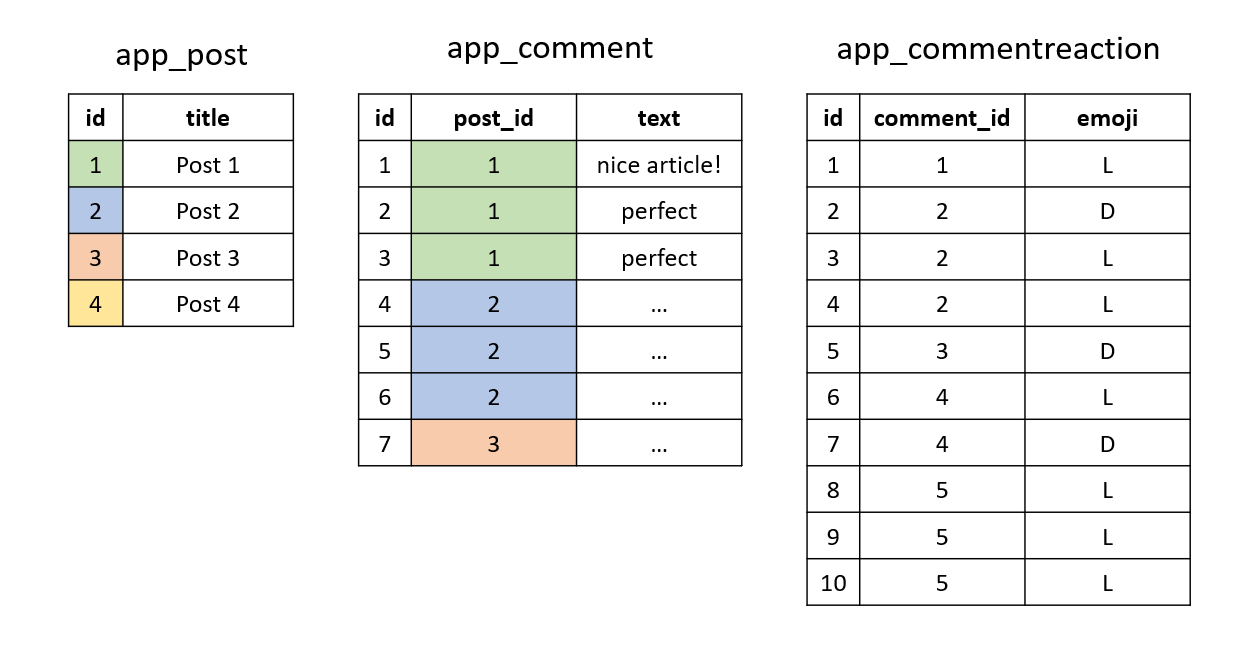
Let's run the query without the WHERE clause:
SELECT * FROM "app_post"
INNER JOIN "app_comment" ON ("app_post"."id" = "app_comment")
INNER JOIN "app_commentreaction" ON ("app_comment"."id" = "app_commentreaction"."comment_id");
We have already seen the result of joining the post table to the comment table. Let's now join the result of that to the comment reaction table to get the result:
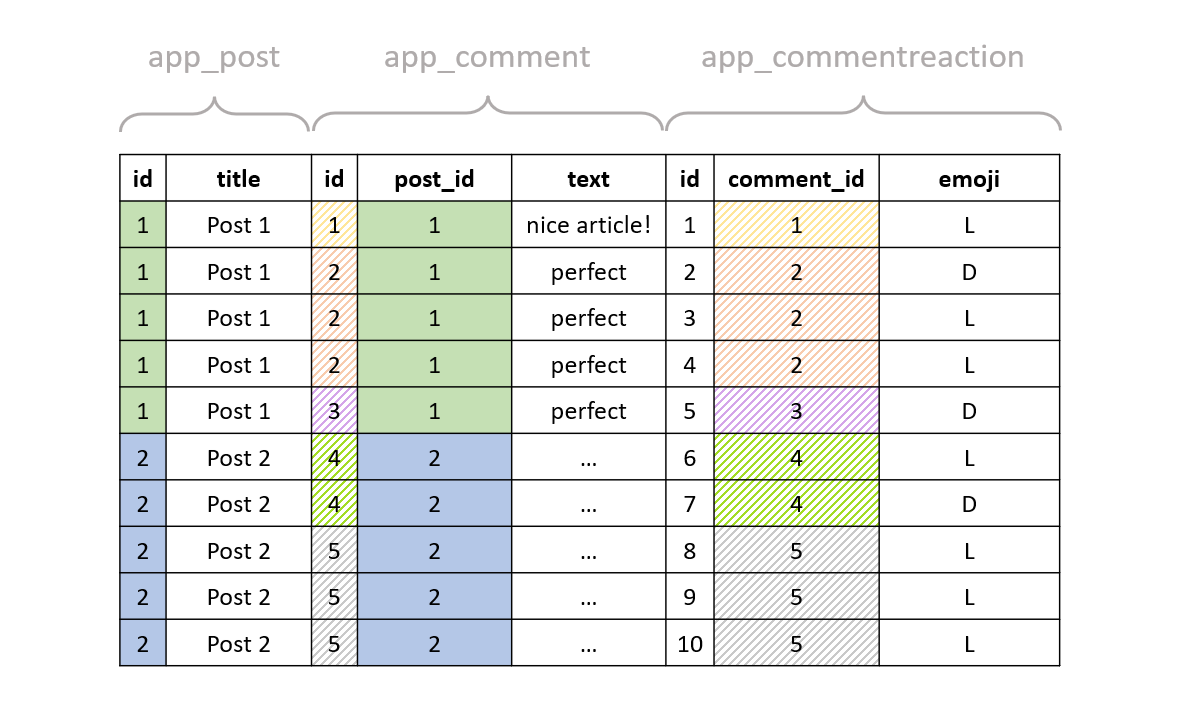
Note how we have 3 rows for the comment with id == 2, but before the last join we had only one such row. Also, we have 5 rows for the post with id == 1, but before the last join with had only 3 such rows. This is because that post had 3 comments (with id's 1, 2 and 3): the first comment had one reaction, the second comment had two reactions, and the third comment had one reaction again, so 5 reactions in total, and thus 5 rows for the post with id == 1.
We finally apply the WHERE clause, which will only keep the rows with a like reaction emoji:
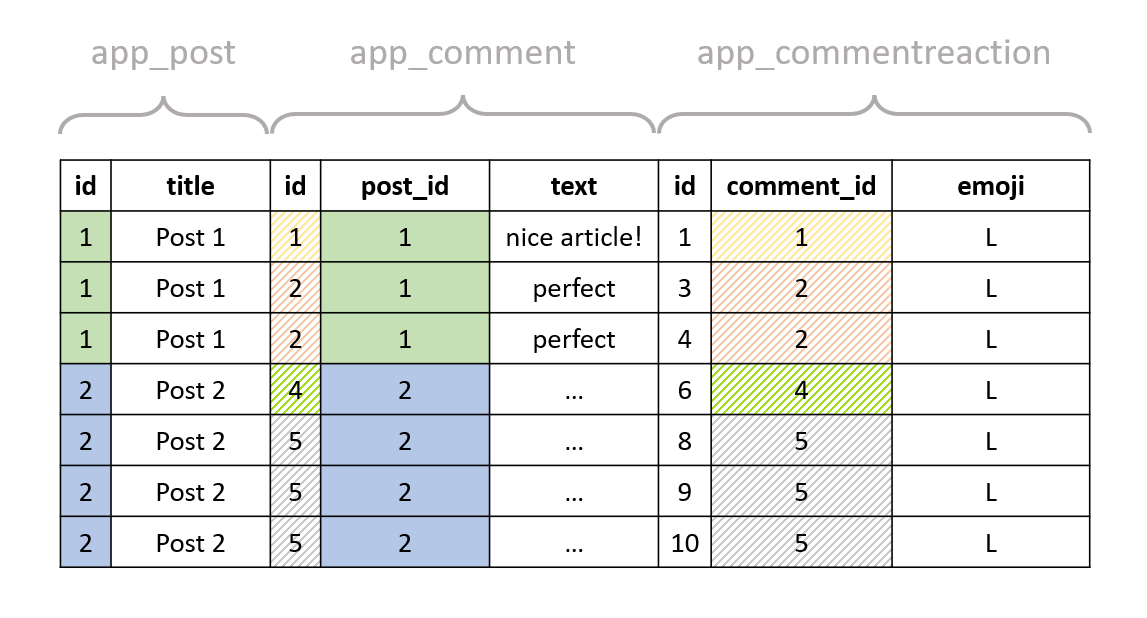
As you can see, there are only two posts that we really want (with ids 1 and 2), but we get 7 items in our resulting queryset. All of this happens because of the way it takes place in the database level. Now, what if we want to get rid of the redundant results?
Excluding the redundant rows
In SQL, there are two major ways of doing this: using DISTINCT, or using GROUP BY. I'm not an SQL expert myself, but apparently in certain cases GROUP BY (with or without aggregates) might perform better than DISTINCT. It's best to test the performance on your database. Let's see how we can use them in Django.
For DISTINCT, we have the queryset method distinct() in Django. For GROUP BY, we can do it with or without an aggregation. The aggregation itself can be useful for further filtering, but you can also only have it as a dummy value merely to make Django include the proper GROUP BY in the query. Let's use aggregation first.
If we want to remove the redundant posts from the result of our last example, we can group by the fields of Post. This way, the rows corresponding to a particular post would be a single "group", and therefore only returned once in the results. As an aside, when you have GROUP BY in your query, anything you put in SELECT must either be in GROUP BY or be an aggregate itself. It's because a column with different values cannot be represented in a single group, unless aggregated in some way, which itself results in a single value. This means that we cannot, for example, select the id and the title of posts but only group by their id.
Here's how we can do it:
Post.objects.filter(comment__commentreaction__emoji='L').annotate(
dummy=models.Count('*')
)
Which corresponds to a query similar to this:
SELECT "app_post"."id", "app_post"."title", COUNT('*') as "dummy" FROM "app_post"
INNER JOIN "app_comment" ON ("app_post"."id" = "app_comment")
INNER JOIN "app_commentreaction" ON ("app_comment"."id" = "app_commentreaction"."comment_id")
WHERE "app_commentreaction"."emoji" = 'L'
GROUP BY "app_post"."id", "app_post"."title";
But what does this annotate() part actually do? First of all, note that by default, Django only does GROUP BY on [the fields of] the original model that we are selecting. In this case, it's Post, so we'll have a GROUP BY on posts (more precisely, on post fields). Therefore, the dummy aggregate will simply be the number of rows that correspond to a particular post, and as we discuessed above, there will be possibly many rows corresponding to each post because of the duplications upon joins. If we look at the result image above, we'll see that the post with id == 1 will have dummy == 3 and the post with id == 2 will have dummy == 4.
But dummy is dummy after all: we didn't need any counting or aggregation in the first place; we just wanted to get rid of the redundant values, and we certainly did:
>>> Post.objects.filter(comment__commentreaction__emoji='L').annotate(
dummy=models.Count('*')
)
<QuerySet [<Post: Post object (1)>, <Post: Post object (2)>]>
We only got distinct post objects.
But let's think about this again: what does dummy actually represent? As we discussed above, it's the number of duplications for each post ... which is exactly the total number of like reactions on each post's comments:
>>> all_results = Post.objects.filter(comment__commentreaction__emoji='L').annotate(
dummy=models.Count('*')
)
>>> post1 = all_results[0]
>>> post2 = all_results[1]
>>> post1.dummy
3
>>> post2.dummy
4
Of course, we could have named it something more appropriate such as total_comment_likes, but naming it dummy in our case was actually better because it emphasizes that fact that we have no other use for the value itself and we only wanted to remove the redundant rows. We could have also not named it at all (by giving it as a positional argument) and let Django automatically choose a name for it.
We can also apply a GROUP BY without aggregates. As we saw, annotate() adds the proper GROUP BY (when there is an aggregation). There is a similar queryset method alias() which does everything that annotate() does, but it does NOT select the value itself; instead, the value can be used in other parts of the query, mainly in conditions. This is useful when we want to filter by a value, but we don't want that value to be SELECTed (note that aggregates are also a part of the SELECT). Replacing the annotate() in above examples with alias() will include the proper GROUP BY, but without the aggregates.
Using aggregation for further filtering
The aggregate value we used above was dummy, but it can actually be useful in other cases. Let's say we want to get all the posts that have at least 3 likes in total on their comments. Can you guess the code? Let's see it:
Post.objects.filter(comment__commentreaction__emoji='L').annotate(
total_comment_likes=models.Count('*')
).filter(
total_comment_likes__gte=3
)
Note that the second filter() has to be used after the annotate(), because it uses a value that is introduced by the annotate(). This time we named the aggregate more properly, because we actually had a use for the count. Also the results will be distinct, because of the GROUP BY due to aggregation. I'd like to show you another example of using aggregate values for filtering, but there is some more complicated stuff we need to understand first, which we'll discuss in the next section.
Single vs multiple filter() calls, and mixing them with annotate()
We have covered a lot so far, but there is one more major detail to cover (at least for this article). We have seen what happens when we have multiple joins in our query: we have duplications every time we make a join over a to-many relation. As we saw, this enables us to make filters based on deeper to-many relations (such as filtering posts based on comment reactions). In the cases we've seen so far, the joins were across different tables (e.g., post to comment, comment to comment reaction), but in some cases we might need to join a table to itself. Let's first learn why, and then how we can do it in Django.
Imagine we want to get all the posts that have a comment with text "great" and a comment with text "perfect". More precisely, we want all the posts that have at least one comment with text "great" and at least one comment with text "perfect". Clearly, a comment's text cannot be both, therefore such a post should have at least two comments. Imagine the following tables:
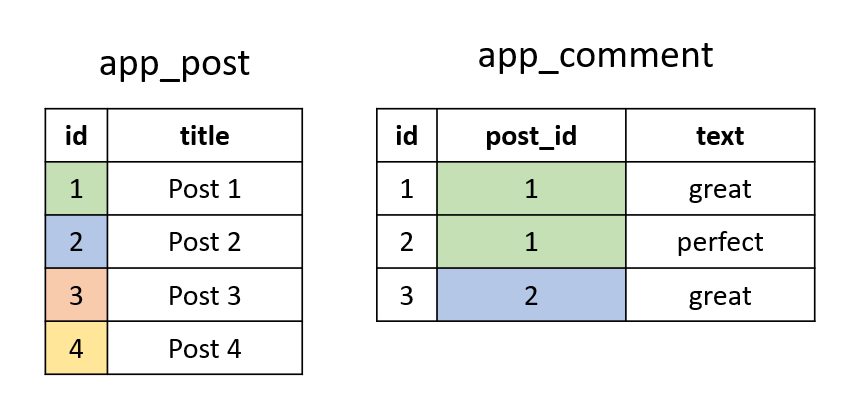
As you can see, the desired result will only contain the post with id == 1, because it has both the necessary comments. The post with id == 2 has the comment with text "great", but not the comment with text "perfect", so it's not qualified. Let's say we join the post table to the comment table:
SELECT * FROM "app_post"
INNER JOIN "app_comment" ON ("app_post"."id" = "app_comment"."post_id");
with the result looking like this:
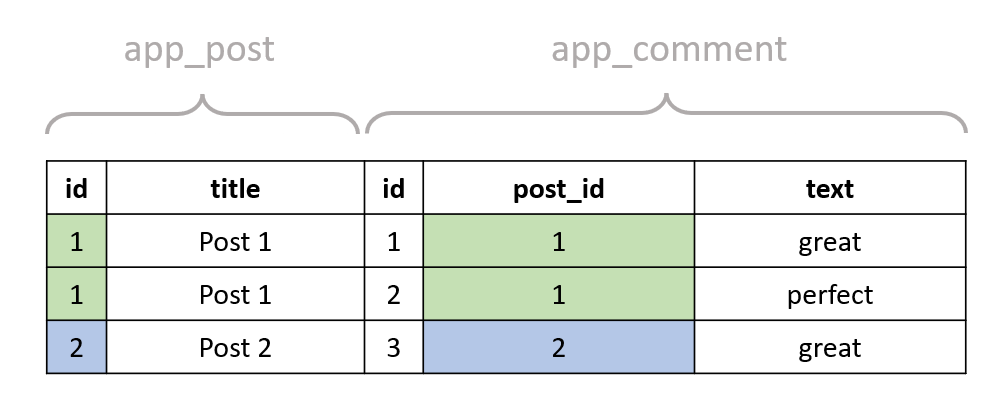
Now, how can we filter out this result to get all the posts that have at least one comment with text "great" and at least one comment with text "perfect"? For example, the following query is not going to work:
SELECT * FROM "app_post"
INNER JOIN "app_comment" ON ("app_post"."id" = "app_comment"."post_id")
WHERE "app_comment"."text" = 'great' AND "app_comment"."text" = 'perfect';
The reason is obvious: both uses of "app_comment"."text" in the condition refer to the value from the same row. In other words, our conditions states that "the comment text should be 'great' and it should be 'perfect'", which is impossible: the text of a certain comment is one thing and one thing only.
We cannot use OR either, because it would also return the posts that only have one of the desired comments: a post that has a comment with text "perfect" but no comment with text "great" (or the other way around) will still be returned.
So, what do we do? Let's try and join the above result to the comment table again (where we have used table aliases T2 and T3 as otherwise we'd have name clashes):
SELECT * FROM "app_post"
INNER JOIN "app_comment" T2 ON ("app_post"."id" = T2."post_id")
INNER JOIN "app_comment" T3 ON ("app_post"."id" = T3."post_id");
And here's the result (note the duplication pattern):
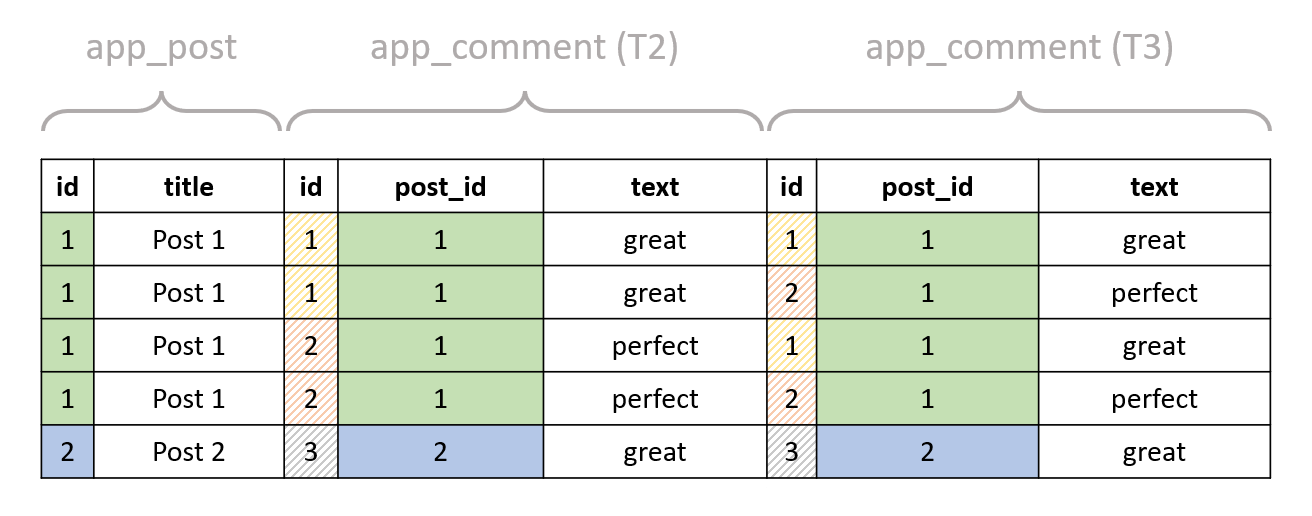
For each comment of every post, the comments of the same post have been included again. This is basically the Cartesian product of the set of comments of each post with itself.
Now, if a post has both the desired comments, then in at least one of the above rows, those two comments will be next to each other. You can see above that the second and third row have one comment with text "perfect" and one comment with text "great", but one is just the reverse of the other. This gives us an important signal: if we filter the rows so that the text from T2 is "great" and the text from T3 is "perfect":
SELECT * FROM "app_post"
INNER JOIN "app_comment" T2 ON ("app_post"."id" = T2."post_id")
INNER JOIN "app_comment" T3 ON ("app_post"."id" = T3."post_id")
WHERE T2."text" = 'great' AND T3."text" = 'perfect';
then we'd actually get the posts we wanted:
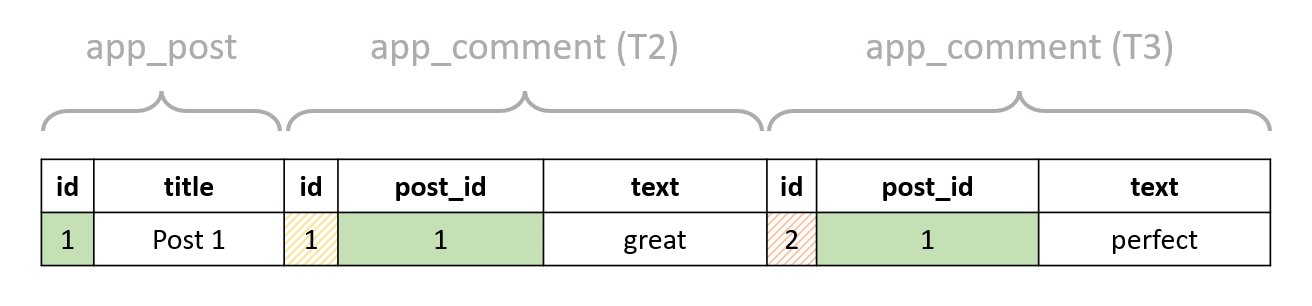
And we didn't get any duplicate results because we used only one of the orders (the other order would be T2."text" = 'perfect' AND T3."text" = 'great'). But if the post with id == 1 had more than one comment with text "perfect" or "great", then we would actually get duplicate results. As an example, imagine these tables:
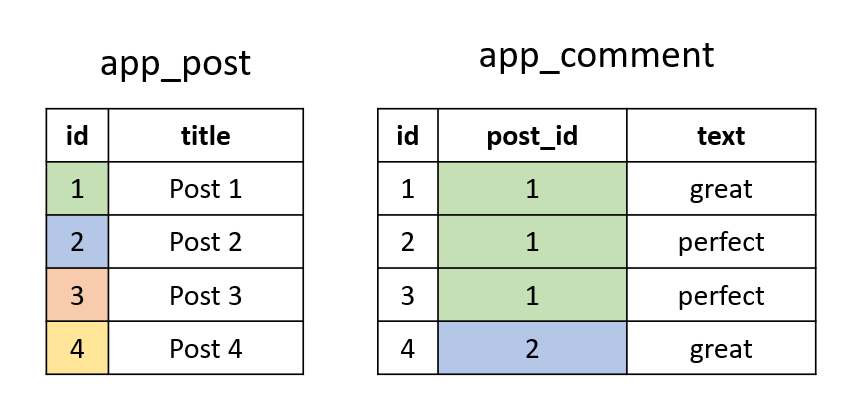
We join to the comment table twice:
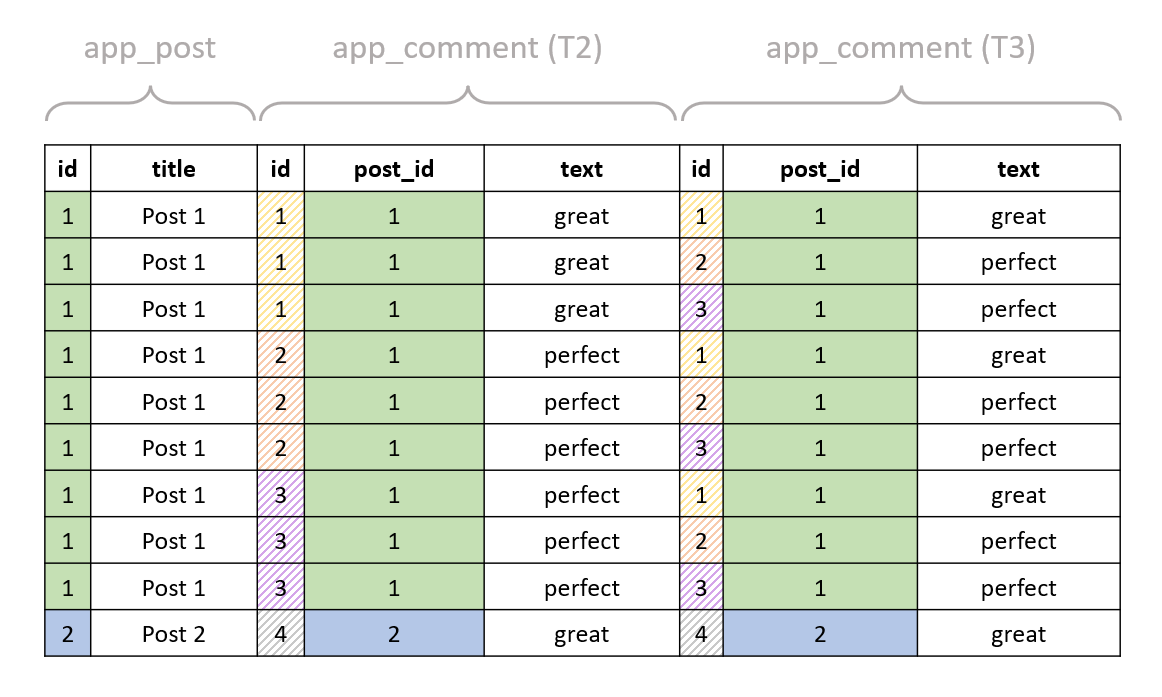
And we filter by T2."text" = 'great' AND T3."text" = 'perfect':
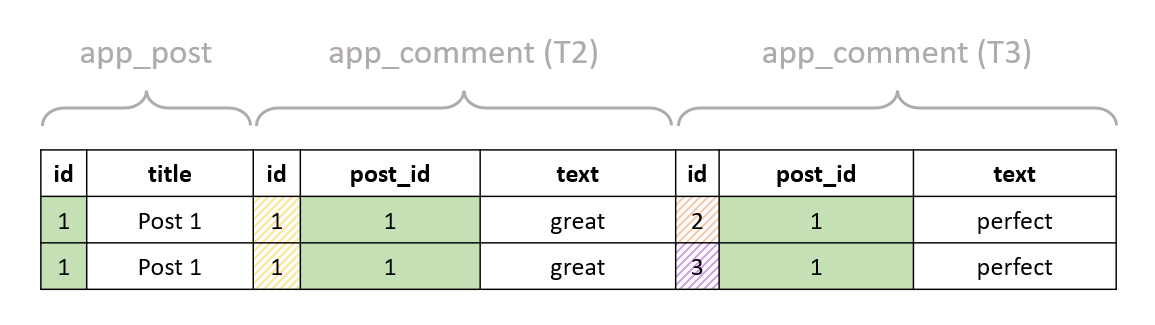
If we had a post that had n comment with text "great" and m comments with text "perfect", that post would be returned n*m times. So, you would have to use the methods we discussed earlier to remove the redundant results if you want.
We have learned how we can do such filters in the SQL level, but how do we translate it to Django's language? The key is: if you want to have multiple joins for filtering your to-many relations, you should put the corresponding conditions in separate filter() calls. For our example, it would be something like this:
Post.objects.filter(comment__text='great').filter(comment__text='perfect')
You learn in Django that when you chain multiple filter()s, their conditions are basically AND'ed together. This is still true in the above code, but we need to understand that even though both conditions are on comment__text, this value is picked from different joined parts, which leads to the desired result. The first filter() will use T2."text" and the second filter() will use T3."text". However, this is only a concern for conditions involving to-many relations, because other types of conditions either don't cause a join (e.g., filtering with post title), or they only involve foreign key relations (i.e., to-one relations), in which case Django will only do a single join and all filters (whether in the same filter() call or separate ones) will refer to that join.
I said that you should put these conditions in separate filter() calls. You might wonder: "But we can't put both of these in a single filter() anyway, because keyword arguments cannot have the same name". The point is that, in the above example both our conditions were an equality check on the text of the comment. What if we want to get all the posts that have at least one comment with text "great" and at least one comment whose text starts with "nice"? Then we'd have to do something like this:
Post.objects.filter(comment__text='great').filter(comment__text__startswith='nice')
In this case, it would be possible (albeit wrong) to put both the conditions in the same filter(), which would return an empty queryset even if we had multiple comments with text "great" or with a text starting with "nice", because the text of a single comment cannot equal "great" and start with "nice" at the same time:
>>> Post.objects.filter(comment__text='great', comment__text__startswith='nice')
<QuerySet []>
It doesn't have to be on the same field either. For example, if the Comment model had a field verified, and we wanted all the posts that had at least one comment with text "great" and at least one comment that is verified, then we could do this:
Post.objects.filter(comment__text='great').filter(comment__verified=True)
What would happen if we put both of these conditions in the same filter()? In that case, the comments would have to satisfy both conditions: having the text "great" and being verified. But we also want to consider the comments that satisfy either of these conditions but not both. So we put them in separate filter() calls. Note that these conditions can overlap, and even if a single comment satisfies both of these conditions, its post would be returned. You might again be tempted to think that this is the same as OR'ing these conditions, but that is not true: if we OR'ed these conditions together, a post that has a comment with text "great" but no verified comment would still be returned.
But there's more: we can actually put the conditions with the same keyword argument name in the same filter(). For that, we would need to use Django's Q objects, which represent conditions:
>>> Post.objects.filter(
models.Q(comment__text='great'),
models.Q(comment__text='nice')
)
<QuerySet []>
But of course, this code is useless and would return an empty queryset as explained.
A similar thing happens when we mix filter() and annotate() where the filter() uses a to-many relation that the annotate() has an aggregate for it. In that case their order becomes important for Django. According to the documentation, "When an annotate() clause is applied to a query, the annotation is computed over the state of the query up to the point where the annotation is requested". As far as I know, this is really a concern when when annotate() has an aggregation for that to-many relation. Let's see what this means (you might have to try these for yourself and inspect the queries to actually understand what is going on).
If you use annotate() to calculate an aggregtion that uses a to-many relation, and then put a filter() after it that uses the same to-many relation, Django will make two joins and calculate each of them on separate joins. But if you put the filter first, Django will only make a single join and calculate both the aggregation and the condition on that join. For example if we have:
Post.objects.annotate(num_comments=models.Count('comment')).filter(comment__text='hi')
The query would be:
SELECT "app_post"."id", "app_post"."title", COUNT("app_comment"."id") AS "num_comments"
FROM "app_post"
LEFT OUTER JOIN "app_comment" ON ("app_post"."id" = "app_comment"."post_id")
INNER JOIN "app_comment" T3 ON ("app_post"."id" = T3."post_id")
WHERE T3."text" = 'hi'
GROUP BY "app_post"."id", "app_post"."title";
As you can see, we have two joins to app_comment. The first join is a LEFT OUTER JOIN, which is the same as INNER JOIN except that it also includes the rows from the first table that have no corresponding rows on the second table. But the following questions arise:
- Why does Django even do two joins in this order?
- Why does Django use
LEFT OUTER JOINfor the first join but anINNER JOINfor the second? - What is the difference between
Count('*')andCount('comment')?
Honestly it can be really confusing, but I'll try my best to explain it.
It all comes down to the unfortunate fact that when the queries become more complicated, translating them from Django's ORM language to SQL becomes more difficult as well. Django tries its best to cover different possibilities by providing different ways to get the right query, such as the subtle behavior for a different order of filter() and annotate(). But Django also wants to keep the ORM as intuitive as possible so that you have to think less about the underlying SQL queries. Thus, Django has to go for a compromise.
Imagine the same code without any filter():
Post.objects.annotate(num_comments=models.Count('comment'))
Looking at this, we can immediately tell that the developer simply wants all the posts, along with the number of comments for each. But if some of the posts have no comment and we use INNER JOIN, they won't show up in the results; clearly not something we want. For this reason, Django uses a LEFT OUTER JOIN, which will include all posts, and the aggregate for the number of comments will simply result 0 if there is no comment for a particular post. Here's the query for it:
SELECT "app_post"."id", "app_post"."title", COUNT("app_comment"."id") AS "num_comments"
FROM "app_post"
LEFT OUTER JOIN "app_comment" ON ("app_post"."id" = "app_comment"."post_id")
GROUP BY "app_post"."id", "app_post"."title";
But then, what is the difference between Count('*') and Count('comment') and why did we use the latter? First of all, we should distinguish SQL's aggregate function COUNT(...) and Django's models.Count(...). The SQL function COUNT(...) can be used in two ways:
COUNT(*): this will count all the rows in each group.COUNT(<expression>): this will count all the rows in each group where<expression>is notNULL.
In our examples, if a post has no comment, then the columns in its comment part will be NULL, and of course we don't want to count them, so we use the latter. But using models.Count('comment') in Django also serves another important purpose: it tells Django what we want to count, and thus which table to join to. If we use models.Count('*'), Django will not do any joins and will just count the number of rows in each group. For example if we do:
Post.objects.annotate(num_comments=models.Count('*'))
Each group will only contain one post, and num_comments would be 1 for all posts (which is, of course, incorrect). So using models.Count(<expression>) instead of models.Count('*') is to achieve either or both of these:
- To tell Django what we want to count, and thus make the proper join(s).
- To only count non-
NULLresults (the SQL side of the behavior).
Now, if we include the filter() after annotate():
Post.objects.annotate(num_comments=models.Count('comment')).filter(comment__text='hi')
What should Django do? If Django does no further joins, then filter(comment__text='hi') will act on the same joined part that we calculate num_comments on. But remember, SELECT is executed after WHERE in SQL, which means that the aggregate would be calculated after the filter. Effectively, we would only count the number of comments with text "hi" for each post. There is nothing wrong with this, except that it is not intuitive to the developer: they used annotate() first, so they might expect Django to count the number of all comments, but then filter them to only include the posts that have at least one comment with text "hi" (rather than only counting those comments). Since Django wants to make it intuitive, it has to make two joins: one LEFT OUTER JOIN to count the total number of comments for each post, and a further INNER JOIN to filter the posts to only include those that have a comment with text "hi". Here's the query:
SELECT "app_post"."id", "app_post"."title", COUNT("app_comment"."id") AS "num_comments"
FROM "app_post"
LEFT OUTER JOIN "app_comment" ON ("app_post"."id" = "app_comment"."post_id")
INNER JOIN "app_comment" T3 ON ("app_comment"."post_id" = T3."post_id")
WHERE T3."text" = 'hi'
GROUP BY "app_post"."id", "app_post"."title";
You can draw the tables for yourself to see it. Now let's reverse their order:
Post.objects.filter(comment__text='hi').annotate(num_comments=models.Count('comment'))
Again, from the perspective of intuition, the developer has used filter first, so they expect that the results are first filtered to only include that posts that have at least one comment with text "hi", and then count the number of comments on each post, which would be the number of comments whose text is "hi". In order to achieve this, a single INNER JOIN is enough, because both operations can use the same joined part:
SELECT "app_post"."id", "app_post"."title", COUNT("app_comment"."id") AS "num_comments"
FROM "app_post"
INNER JOIN "app_comment" ON ("app_post"."id" = "app_comment"."post_id")
WHERE "app_comment"."text" = 'hi'
GROUP BY "app_post"."id", "app_post"."title";
Finally, I'll show the example I promised in the previous section. Let's say we want to get all the posts that have at least 3 comments with each of them having at least one like reaction. Since we want the number of comments for each post, we cannot join to the comment reaction table, because that would cause duplication for each comment. So, we'll use a subquery that retrieves all the comments of each post that have at least one like reaction, and filter the rows so that the comments are only from the subquery:
Post.objects.annotate(total_comments=models.Count('*')).filter(
comment__in=models.Subquery(
Comment.objects.filter(
post=models.OuterRef('id'),
commentreaction__emoji='L'
).only('id')
),
total_comments__gte=3
)
In this case, there is no difference between using models.Count('*') and models.Count('comment') in terms of joins, because the filter that comes after it causes a join to the comment table anyway; however, as we discussed above, if we use models.Count('comment') but annotate() comes before filter(), then we wouldn't get the right result, because Django would make a separate join to the comment table to count all the comments, rather than only those that pass the filter. So, one can still use models.Count('comment') in the above code as well (which is unnecessary), but they would have to switch the places of annotate() and filter(). But total_comments is a value that is introduced by annotate(), so we cannot use it before annotate(). Thus, we have to add another filter() after annotate() that does the filter on total_comments. This doesn't cause a problem for filter()/annotate() order, because the filter() that uses the to-many relation comment still comes before the annotate() that uses it:
Post.objects.filter(
comment__in=models.Subquery(
Comment.objects.filter(
post=models.OuterRef('id'),
commentreaction__emoji='L'
).only('id')
),
).annotate(total_comments=models.Count('*')).filter(
total_comments__gte=3
)
Phew!
Finally ...
What is the point of this heck ton of details? I think it's worth going through at least once. You don't really need to remember all of this. What you need to be able to do is inferring these based on the code, its query and Django's docs. If you want to see the query of a queryset, simply use the query attribute on it:
print(Post.objects.filter(title='Post 1').query)
Sorry if my language gets repetitive in certain points, but I think when it comes to technical details, repetitive language is better than ambiguous language. That's why you might see some words being overused.